How to Represent Meaning in Natural Language Processing? Word, Sense and Contextualized Embeddings
Written by Jose Camacho Collados and Taher Pilehvar
Word embeddings are representations of words as low-dimensional vectors, learned by exploiting vast amounts of text corpora. As explained in a previous post, word embeddings (e.g. Word2Vec [1], GloVe [2] or FastText [3]) have proved to be powerful keepers of prior knowledge to be integrated into downstream Natural Language Processing (NLP) applications. However, despite their flexibility and success in capturing semantic properties of words, the effectiveness of word embeddings is generally hampered by an important limitation, known as the meaning conflation deficiency: the inability to discriminate among different meanings of a word.
A word can have one meaning (monosemous) or multiple meanings (ambiguous). For instance, the noun mouse can refer to two different meanings depending on the context: an animal or a computer device. Hence, mouse is said to be ambiguous. According to the Principle of Economical Versatility of Words [4], frequent words tend to have more senses, which can cause practical problems in downstream tasks. Moreover, this meaning conflation has additional negative impacts on accurate semantic modeling, e.g., semantically unrelated words that are similar to different senses of a word are pulled towards each other in the semantic space [5,6]. In our previous example, the two semantically-unrelated words rat and screen are pulled towards each other in the semantic space for their similarities to two different senses of mouse. This, in turn, contributes to the violation of the triangle inequality in euclidean spaces [5,7]. Therefore, accurately capturing the semantics of ambiguous words plays a crucial role in the language understanding of NLP systems.
In order to deal with the meaning conflation deficiency, a number of approaches have attempted to model individual word senses. The main distinction of these approaches is in how they model meaning and where they obtain it from:
- Unsupervised models [5,8,9] directly learn word senses from text corpora.
- Knowledge-based techniques [6,10,11] exploit the sense inventories of knowledge resources (e.g. WordNet or BabelNet) as their main source for representing meanings.
Each approach has its own advantages and disadvantages. For instance, knowledge-based models have the advantage of better interpretability, and the fact that they can benefit from knowledge encoded in lexical resources (e.g., definitions, properties or images). However, all senses have to be contained in a knowledge base, which has to be constantly updated. On the other hand, unsupervised models are easily adaptable to different domains, although this makes them highly biased to the underlying training corpus, which can potentially result in missing specialized senses.
Moreover, both kinds of approach suffer from the difficulty of linking learned representations to text representations, as this step requires accurate disambiguation models. In the case of knowledge-based systems, current disambiguation systems are far from perfect [12], as state-of-the-art supervised systems need vast amounts of training data. This data is highly expensive to obtain in practice, which causes the so-called knowledge-acquisition bottleneck [13].
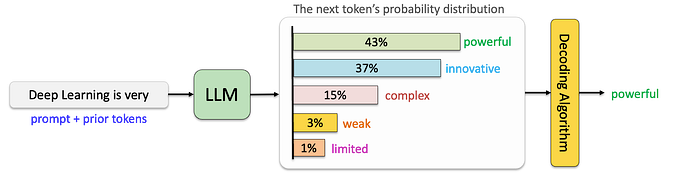
As a practical way to deal with this issue, an emerging branch of research has focused on directly integrating unsupervised representations (learned by leveraging language models) into downstream applications. Instead of learning a fixed number of senses per word, contextualized word embeddings learn “senses” dynamically, i.e., their representations dynamically change depending on the context in which a word appears. Context2vec [14] is one of the pioneers for this type of representation. The model represents the context of a target word by extracting the output embedding of a multi-layer perceptron built on top of a bi-directional LSTM language model. More recently, this branch has been popularized by ELMo [15], where a seamless integration of these representations into neural NLP systems was proposed, and more recently BERT [16]. At test time, a word’s contextualized embedding is usually concatenated with its static embedding and fed to the main model, as shown in the following figure.
This way the main system benefits from static and dynamic word representations at the same time, and without the need for disambiguation. In fact, the integration of contextual word embeddings into neural architectures has led to consistent improvements over important NLP tasks such as sentiment analysis, question answering, reading comprehension, textual entailment, semantic role labeling, coreference resolution or dependency parsing [16,17,18,19].
Even with these groundbreaking results, there is definitely room for improvement. In a recent study we analyzed how well sense and contextualized representations capture word meaning in context (WiC) [20]. The results show how state-of-the-art sense and contextualized representation techniques fail at accurately distinguishing meanings in context, performing only slightly better than a simple baseline, while significantly lagging behind the human inter-rater agreement of the dataset (best model at around 65% accuracy with respect to the human performance over 80%). This suggests that the improvements of contextualized embeddings may not be due to a perfectly accurate capturing of meaning, but rather a first step towards this direction. In fact, static (context-independent) word embeddings cannot be completely replaced by contextualized embeddings, as they still play an important role in these systems.
For more information on vector representations of meaning, we recently published a more comprehensive survey on this topic for the Journal of Artificial Intelligence Research (JAIR): “From Word to Sense Embeddings: A Survey on Vector Representations of Meaning”.
— — —
[1] Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. Efficient estimation of word representations in vector space. CoRR abs/1301.3781. https://code.google.com/archive/p/word2vec/
[2] Jeffrey Pennington, Richard Socher, and Christopher D. Manning. 2014. GloVe: Global vectors for word representation. In Proceedings of EMNLP, pages 1532–1543. https://nlp.stanford.edu/projects/glove/
[3] Piotr Bojanowski, Edouard Grave, Armand Joulin, and Tomas Mikolov. 2017. Enriching word vectors with subword information. Transactions of the Association of Computational Linguistics, 5(1):135–146. https://github.com/facebookresearch/fastText
[4] George Kingsley Zipf. 1949. Human behavior and the principle of least effort: An introduction to human ecology. Addison-Wesley, Cambridge, MA.
[5] Arvind Neelakantan, Jeevan Shankar, Alexandre Passos, and Andrew McCallum. 2014. Efficient non-parametric estimation of multiple embeddings per word in vector space. In Proceedings of EMNLP. Doha, Qatar, pages 1059–1069.
[6] Mohammad Taher Pilehvar and Nigel Collier. 2016. De-conflated semantic representations. In Proceedings of EMNLP, Austin, TX, pages 1680–1690.
[7] Amos Tversky and Itamar Gati. 1982. Similarity, separability, and the triangle inequality. Psychological review 89.2: 123.
[8] Joseph Reisinger and Raymond J. Mooney. 2010. Multi-prototype vector-space models of word meaning. In Proceedings of ACL, pages 109–117.
[9] Jiwei Li and Dan Jurafsky. 2015. Do multi-sense embeddings improve natural language understanding? In Proceedings of EMNLP. Lisbon, Portugal, pages 683–693.
[10] Massimiliano Mancini, Jose Camacho-Collados, Ignacio Iacobacci, and Roberto Navigli. 2017. Embedding words and senses together via joint knowledge-enhanced training. In Proceedings of CoNLL, Vancouver, Canada, pages 100–111.
[11] Sascha Rothe and Hinrich Schütze. 2015. Autoextend: Extending word embeddings to embeddings for synsets and lexemes. In Proceedings of ACL. Beijing, China, pages 1793–1803.
[12] Alessandro Raganato et al. 2017. Word sense disambiguation: A unified evaluation framework and empirical comparison. In Proceedings of EACL. Valencia, Spain, pages 99–110. http://lcl.uniroma1.it/wsdeval/
[13] William A. Gale, Kenneth Church, and David Yarowsky. 1992. A method for disambiguating word senses in a corpus. Computers and the Humanities 26:415–439.
[14] Oren Melamud, Jacob Goldberger, and Ido Dagan. 2016. Context2vec: Learning generic context embedding with bidirectional LSTM. In Proceedings of CoNLL, Berlin, Germany, pages 51–61.
[15] Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. 2018. Deep contextualized word representations. In Proceedings of NAACL, New Orleans, LA, USA, pages 2227–2237. https://allennlp.org/elmo
[16] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805. https://arxiv.org/abs/1810.04805
[17] Bryan McCann, James Bradbury, Caiming Xiong, and Richard Socher. 2017. Learned in translation: Contextualized word vectors. In Proceedings of NIPS, Long Beach, CA, USA, pages 6294–6305.
[18] Shimi Salant and Jonathan Berant. 2018. Contextualized word representations for reading comprehension. In Proceedings of NAACL (short), New Orleans, LA, USA, pages 554–559.
[19] Wanxiang Che, Yijia Liu, Yijia Wang, Bo Zheng, and Ting Liu. 2018. Towards better UD parsing: Deep contextualized word embeddings, ensemble, and treebank concatenation. In CoNLL 2018 Shared Task: Multilingual Parsing from Raw Text to Universal Dependencies.
[20] Mohammad Taher Pilehvar and Jose Camacho-Collados. 2018. Wic: 10,000 example pairs for evaluating context-sensitive representations. arXiv preprint arXiv:1808.09121. https://arxiv.org/abs/1808.09121